张家口集团该如何做监控系统
发布日期:2020-01-20 浏览次数:
张家口集团该如何做监控系统,目前系统监控的手段比较多,大致可以分为三类:业务监控,应用监控和系统监控。
业务监控监测业务指标,比如下单量,用户注册数等,从业务数据来评估当前系统是否正常。
应用监控针对具体的应用,一般从接口调用的角度检测应用状态,比如调用数量 / 响应时间 / 错误数等,有很多 APM 工具可以做到这点。
系统监控针对物理机器资源,比如 CPU/ 内存 / 磁盘使用情况等,Zabbix 是典型的工具。
这些监控针对不同维度,监控结果在不同的系统里输出,比较分散;而且由不同的人负责,比如运维负责 Zabbix,开发负责应用监控。在系统真正出问题的时候,从发现问题到定位问题,再到解决问题,协作困难,造成事故时间长,业务影响大。
本人基于实际的监控痛点,通过一体化地监控手段,比较高效地解决大型系统的监控问题,这里抛砖引玉,和大家探讨一下。
本文的内容包括:
1) 监控痛点
2) 解决思路
3) 架构方案
4) 监控效果
5) 总结
1. 监控痛点
大型的互联网平台,特别是面向 C 端的交易类系统,当线上发生问题,通常要求分钟级的处理速度。比如美团 / 饿了吗外卖平台,停摆 10 分钟,相信无数的商家 / 骑手 / 消费者会大规模投诉,这不仅是经济损失,平台商誉也会受严重影响。
这些平台背后都是大规模的分布式系统,有各种应用,还有基础组件 (数据库 / 缓存 /MQ 等),共同组成复杂的依赖网络,任何节点都可能出问题,导致系统不可用。这样对系统的监控就非常重要,通过监控,及时干预,避免事故或缩短事故时间。
大型交易类平台监控还是相对完善的,一般由很多块屏幕组成一个屏幕墙,包括业务曲线监控(业务监控),关键应用的接口调用和出错情况(应用监控),网络和数据库监控(系统监控),但是事故发生时,还是一大堆人手忙脚乱,无所适从。
这里举一个典型的线上事故处理例子:
Monitor 发现订单曲线突然跌停,快速拉起电话会议或群里 @大堆的人排查。
运维检查网络和机器,开发检查错误日志,DBA 检查数据库。然后负责 APP 服务端的开发在 ELK 发现大量的调用下单服务超时,询问下单服务怎么回事,并给出调用例子;下单服务根据调用例子检索错误日志,发现调用会员服务大量超时,问会员服务怎么回事;会员服务检索错误日志,发现访问会员数据库连接超时,问 DBA 怎么回事;DBA 拉上网络同事一起看,发现网络没问题,而是会员数据库有慢查询把 DB 挂住;最后 DBA 把慢查询杀掉,系统暂时恢复正常,大家都松了一口气。这个时候距离问题发生已经过去很长时间。在此期间,技术总监被 CTO 催了 N 次,CTO 被 CEO 催了 2N 次,CEO 被客户催了 N x N 次,客户被消费者投诉了 N x N x N 次。
可以看到,虽然有很多监控手段或者大屏监控,但真正出事故时,能发挥的用处还是比较有限,那这里面具体有哪些问题呢?
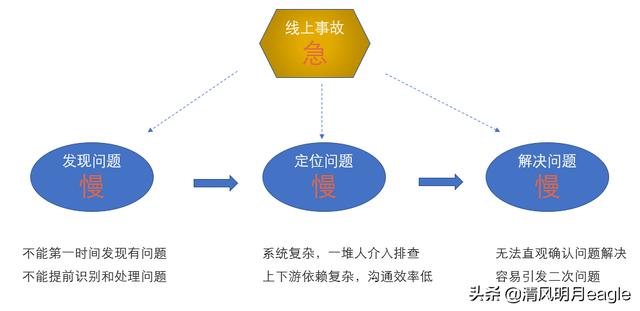
第一发现问题慢,业务曲线一般 1 分钟更新一次,有时候因为正常的业务抖动,还需把这种情况确认排除掉,带来很大的滞后性。
第二定位问题慢,系统庞大,大量的人需要介入排查,而且由于依赖复杂,需要反复沟通才能串起来。一方面无关的人卷入进来,人员浪费,另一方面沟通效率低,定位问题时间长。
第三解决问题慢,当定位到问题,对系统进行调整后,验证问题是否解决也不是容易的事。更新大量机器需要时间,然后需要各个研发确认系统有没问题,还要通过滞后的业务曲线看业务是否恢复。有时病急乱投医,往往会发生二次事故,这里的问题是缺乏实时直观的反馈途径。
2. 解决思路
如何有效解决监控上的这些痛点,快速处理线上事故呢?
我们可以借鉴道路交通监控的例子,在交通监控图上,每条道路通过上下左右方位有机地关联在一起,形成整体的交通网络,同时通过红黄绿三种状态实时反映拥堵情况。司机可以非常直观地获取信息,及时避开拥堵路段,如下图所示:
这里有几个关键词:实时,整体,直观。
首先要实时,马上知道系统当前是否有问题。
然后要针对系统做整体监控,把各个部分放一起,能够迅速识别哪些部分是好的,哪些部分不好。有问题的部分,又有可能是它依赖的部分引起的,因此依赖关系也要直观展示,便于定位真正的问题源。
最后要直观,发生紧急事故时,人脑处于错乱状态,这时候,不能借助专业的头脑或严密的分析才能判断。哪些部分有问题,问题严重程度,以及出问题的原因必须一目了然,不能连累他人。谁家的娃有问题,各找各妈,各回各家。
如果我们能按照道路交通监控的思路,对我们的系统提供类似的监控,那就非常理想,每个系统节点对应一条道路,应用的健康状况对应道路拥堵情况,应用的上下游依赖关系对应道路的方位关系,这样我们就能构建一个实时直观的一体化监控体系。

回到刚才的例子,我们的系统交通图监控如此设计,首先聚合层应用,各种服务(下单服务,会员服务,商品服务,库存服务,促销服务等),各个服务对应的 Redis,MQ 和数据库,这些节点按照相互调用关系放在一张图里。出上述问题时,聚合层应用 ->下单服务 ->会员服务 ->会员数据库这 4 个节点都会爆红,其他节点保持绿色。前 3 个节点有错误消息提示接口调用超时,会员数据库节点提示数据库连接超时。这样首先其他节点可以不用排查,然后观察爆红的节点,通过直观的上下游依赖关系,知道最终问题很可能出在会员数据库上,DBA 重点检查这个就可以。数据库问题解决后,可以看到爆红的节点马上变绿,整个系统恢复正常。
3. 架构方案
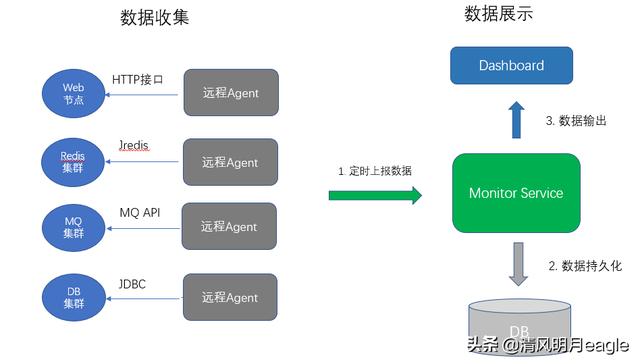
整个系统架构如上图所示,每个被监控节点,均有对应的 agent 负责采集健康数据,不同的节点类型,采集的方式不一样,web 节点提供 http 接口,agent 定时访问,Redis 和 MQ 通过对应的 api,db 则采用标准的 jdbc。除了 web 应用有少量改造(提供一个接口),其他节点都无需改造,系统的侵入性很低。
Agent 每 5s 采集节点数据,由 monitor service 确定节点当前状态并存储,Dashboard 每 3s 拉取节点状态并以红黄绿三色展示,同时显示具体出错信息。
4. 落地效果
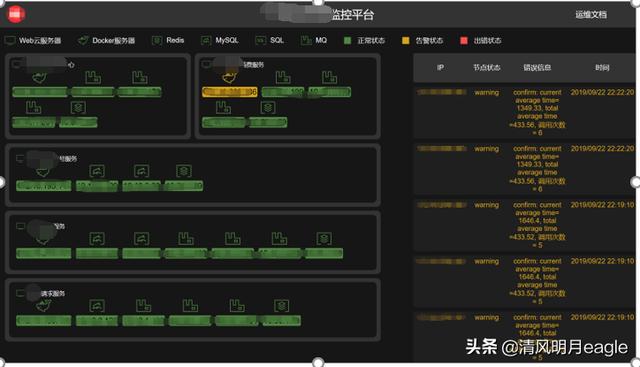
看下实际监控效果,下图是某个业务系统的实际监控效果图,左边是系统部署架构,最上面是两个前端应用,分别有自己的 Web 服务器(Docker 部署,所以只显示一个节点实例),以及 MQ 和 Redis 中间件(有多个节点实例),这两个应用同时依赖后端 3 个服务,实际节点部署情况和依赖关系一目了然。
图中有一个节点是黄色状态,原因是采样时间内接口平均调用时间超过正常数倍。其他节点均正常,具体出错信息在右边列表有说明。点击某个节点,会显示该节点历史出错信息,可供进一步排查,这里就不贴截图了。
这是单个系统的监控,用一个单独的页面表示,如果一个公司有多达数十套系统,对应数十个页面,monitor 肯定看不过来,屏幕墙物理空间也有限。这里可以进一步做所有系统的大盘监控,每个系统在大盘上用一个方块表示,同样有红黄绿三种状态,这个状态是根据该系统内所有节点状态加权算出。
此外,如果具体节点实例有问题,会在大盘左侧区域按照类别汇总显示,出错信息在大盘下方展示。这张图兼顾宏观和微观,一方面直观展示各个系统总体状况,另一方面展示所有问题节点的出错情况。Monitor 只要观察这个大盘页面就可以,如果发现某个系统有问题,可以点击进去,看该系统详细出错情况。
下图有一个系统处于红色高危状态,两个系统是黄色警告状态,引起这 3 个系统出问题的是 3 个 web 节点,在左边显示,具体出错信息在最下面的错误列表。这里系统状态,节点状态,错误消息均以红黄绿表示,可以非常直观地对应起来。

通过一体化地交通图监控,可以快速定位到哪些节点有问题,通过依赖关系进一步确定问题源,并且有具体的出错信息可以帮助定位原因,配合在一起,大大减少问题解决的时间。
5. 总结
交通图监控有以下特点:
- 包含节点 ->应用 ->系统 ->大盘监控,层次鲜明,依赖清晰,实现一体化监控。
- 直观地以红黄绿展示节点状态,每个人都能判断哪里有问题,以及问题原因。
- 本质上这是一个活的部署图,实时反映系统状态,并和实际部署一模一样。
常规的监控工具,比如 Zabbix 和 APM,强调微观,适合程序员排查具体问题。
交通图监控强调更宏观一些,自上而下地把监控对象组织在一起,把所有人拉到同一个信息层面,并提供直观的手段标识问题,非常适合解决线上重大事故。
当然两者完全可以结合起来,交通图监控作为监控大屏入口,常规监控作为细节补充。在我们的节点详情页里,也是有链接指向该节点的 Zabbix 和 CAT 监控页面,可以帮助获取错误详细信息。张家口集团该如何做监控系统- 上一篇:张家口集团怎么做监控
- 下一篇:张家口监控如何做
