
![[field:title /]](/style/images/star.png)

游戏、广告、电商是互联网3大现金流业务,2016年腾讯广告收入增长54%达到270亿。本次分享和大家一起探讨了在数据量急剧增长的情况下腾讯大统一广告系统的广告业务有什么特点,对技术架构有什么特殊的需求,支持和推动腾讯社交与效果广告的技术架构是怎么样的?社交、效果与品牌广告的大统一广告系统该具备什么样的架构形态和基础能力?

以下为唐溪柳演讲实录
大家好,非常高兴能有机会和大家分享一下腾讯社交与效果广告系统。
腾讯社交与效果广告(SPA)从最开始的广点通发展到现在,从每天收入百万级到现在的千万级,直至未来系统承载的目标可以达到每天亿级以上。这套架构经历了很多年的演变,核心一直没有太大的变化,这里给大家分享一下我们架构的方法论和演进的过程。
我的分享分成几个部分,首先介绍一下系统架构,然后是SPA研发体系,然后介绍一下架构中几个比较有意思的系统,一个是检索系统,也是我们这个架构的核心,另外是数据分析引擎。
系统架构

这是我们SPA整个业务的系统架构,大家可以看到,这里比较粗的黑线,是系统的数据流,数据是我们这个系统非常关键的因素,我们整个系统构建在数据的基础上,利用数据来不断的去优化这个系统。这种业务模式实际上是互联网中比较经典的业务模式,包括搜索、广告、电商,都是基于数据的大系统。腾讯SPA广告系统是比较好的数据驱动业务的模型。
整个广告系统可以分几个部分,最底层是广告引擎,这对于我们系统来说处于发动机的位置。为什么叫它发动机呢?因为广告引擎的作用是把流量端,例如微信、QQ,和广告侧的广告数据做一个匹配运算,万里挑一,从几十万广告中挑出前100广告。
然后是我们的播放平台,会做一些和播放有关的策略。然后是投放平台,是我们和广告主的接口,广告主投放创意,观察它的投放效果。下面是日志平台,每个数据的生产点不一样。在每个请求上面都有一个请求日志,广告曝光后有曝光日志,用户点击后有点击日志,如果发生了转化,广告主也会给我们转化数据。这些数据是用户在系统某一个时间点的切片,他们在时间轴上是不一样的,所以我们需要有一个系统把所有的数据对齐,我们把它称为日志处理平台。它将数据反馈到模型训练平台,这里可以利用数据进行学习和预测。广告系统还有垂直的业务,比如DMP数据管理平台,在这里广告主可以上传自己的用户数据,和腾讯内部的用户数据做一个交叉分析,得出他感兴趣的人群。
下来我会过一下系统的数据流,会先从广告主一侧过,然后再从流量过。
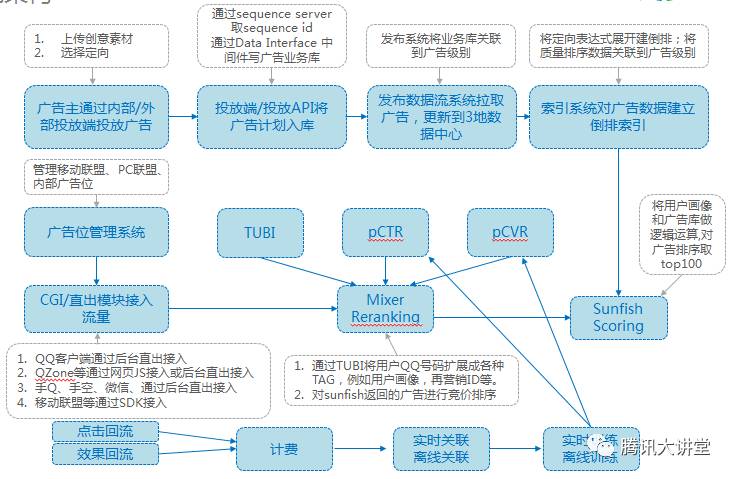
广告主第一个行为是上传他的广告,设计一个创意,选择一个定向,上传这个广告。有了这个行为之后,系统会自动将广告插入到广告库,除了正常的数据库操作还会产生一个流水序列号,这对于我们系统来说就相当于一个心跳,它对于我们系统的稳定性非常关键。我们利用了一个开源软件zookeeper,利用了5台机器搭建的集群来产生一个序列号。因为有5台,可以容灾,只要3台正常工作,整个系统就可以正常工作。整个系统通过流水驱动接下来的流程。然后有一个发布系统,它会根据流水将广告库扩展到广告级别,部署到天津、上海、深圳三地的数据中心。然后有一个检索系统,建立倒排表,将广告质量的数据流关联到广告级别,生成索引文件。我们有了索引文件之后,会加载我们的索引文件,对外提供服务。
接下来是流量侧。首先有一个广告位管理系统,我们有一个移动联盟的业务,它有几十万的广告位,对于这么大规模的广告位,人工的方式没有办法管理,所以我们研发了一个广告位的管理系统。我们有多种接入,我们在CGI这个模块把所有的接入变成一个通用的请求,对后端屏蔽具体的接入方式。在Mixer这个模块,我们会把用户的QQ号扩展成用户的年龄性别,还有很多垂直的业务,例如再营销,用户在电商平台的一些用户行为,比如说下单、收藏这些行为,也是在这里进入到我们的系统。Mixer将流量端用户标识扩展出用户画像后,会请求检索系统,我们会把它和广告数据关联起来运算。对于检索系统的返回,对每个广告会请求点击率预测和转化率预测服务,利用这些预测的值乘上广告的出价,形成一个打分叫做ECPM,我们用它进行排序,形成最有价值的广告返回给流量侧。
大家从前面的流程中可以看到,我们的整个广告系统是一个链条比较长的系统,整个广告系统可能是一串项链,由很多珍珠串起来的。当某一个需求要落地的时候,要关联到许多环节。我们现在有几十种网络服务,每天有一百多次变更,整个部门有几百工程师,线上有一万多台服务器,总计800多万行源代码。整个部门的收入,每天几千万。这里有一个冲突,怎么在需求的变更和系统稳定性之间找到一个平衡,因为整个系统线上每天产生几千万收入,如果遇到代码的BUG或者发布的问题,这是要被问责的,因为造成了亏损。我们怎么解决?经过了思考和创新,总结了一套打法,或者说最佳实践。首先统一代码规范,在底层研发了一个构建系统Blade,我们强制所有代码都必须有代码评审,然后才能提交。然后是自动化工具检查、持续集成系统。经过一系列的方法论或者规范之后,我们在稳定性和敏捷性中取得了平衡。
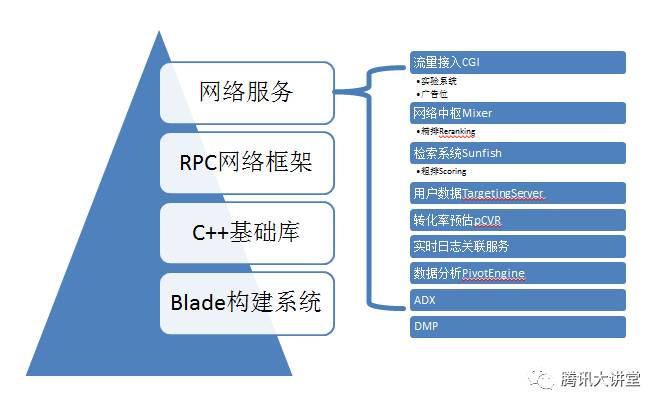
大家可以看到,我们系统从是一个长链条的系统,但是如果对每一个网络服务来看,我们是分层的。最底层是构建系统,我们在构建系统上集成了很多对大规模软件工程的理解,例如集成了对单元测试的比较好的支持,集成了对内存泄露检测的支持,集成了对protocol buffer的支持,protocol buffer的生成文件不用提交到代码库,这样保持代码库的干净和整洁。在Blade之上有一个基础库,例如对文件系统的封装,就是文件类,可以统一访问本地文件或者网络文件。C++访问hdfs比较麻烦,我们抽象出来之后,集中精力解决大家认为棘手的问题,让所有使用这个文件类的人都得到了收益。这个C++是内部开源的,大家可以看一下。在C++基础之上有一个RPC网络框架,加上Blade的支持,在我们这里开发一个网络服务是非常容易的。在网络框架之上是各种各样的网络服务,我们就是利用这些网络服务构建了整个SPA的架构,现在每天流水七千多万。大家可以看一下,上面有流量接入的CGI,这里有一个实验系统,可以对系统变更做一个监测。里面有一个精排,可以对检索系统返回的广告做百里挑十、百里挑一的排序。所有这些服务都是基于同样的网络框架,所以我们可以做一个比较好的运维。
检索服务

接下来讲一下网络服务里面比较有意思的检索服务。大家可以看到,检索服务在链条的中间位置,之前没有用户数据,之后没有广告数据,所以这个检索是两路数据的交汇点。
我们对检索服务经过了三版的迭代,第一次实现的时候是采用传统的倒排表的形式,例如把年龄、性别、规格、地域等进行组合。在倒排表之后做过滤的逻辑。这个架构面临着一些问题,首先它的复杂度是M×N。但是广告的增加是我们业务的驱动力,比如说在电商大促,广告数量要翻一番,这时候系统的性能会急剧下降。还有一个挑战,因为它只有6个维度进入倒排,超过6个维度,就需要用代码实现定向逻辑。但实际上定向产品是广告产品的驱动力,我们倾向于添加越来越多的定向产品,这样会导致代码越来越复杂,最终会导致代码失控。
接着我们开发出了第二代系统,我们做的第一件事情是把定向接口抽象化成一颗四层的树,它实际上是一颗四层的逻辑树。在离线的时候,把它变成三层结构。解决了随着广告数增加,算法性能下降的棘手问题。第二代系统上线之后有比较好的效果,首先是增加定向,你不用再改代码了,这是最大的好处。还有其他的好处,因为索引和定向接口标准化,减少了很多沟通的工作。还有定向维度进入倒排,增加定向产品不会导致性能下降。但是后来也遇到了一些挑战,第一是索引和排序之间的挑战,遇到的是检索和排序之间的问题,它们是通过数据来耦合,在需求变更的时候要频繁的修改这个接口。第二是所有的定向都是在统一的64位空间里,这个时候就没有办法支持不同空间的信息混排。例如分类的时候,苹果不知道是分到水果还是3C里面。没有提供一个维度的命中信息,例如命中了苹果,不知道这个广告被触发是因为命中了苹果,而不是其他的东西。
所以有了第三代系统,2013年12月份提出要开发第三代系统,2014年5月份全面上线,我们在Query和广告这两端都能够支持定向的表达式,目前来看是处在行业领先的水平。第三代系统的特点,首先它有更强的定向能力,因为它不是四层树,而是递归多叉树,然后是把排序接口标准化,大家可以通过它来开发和沟通。还有一个比较关键的特性是它能够融合各种用户标识,腾讯内部有很多用户标识,例如QQ号、微信号,还有IMEI、浏览器也有自己的标识。这个系统具备的能力是能够把各个接口打通,这是我们这个系统能够成功融合的关键特性。第四是支持不同空间信息的混排,每个定向ID都属于同一个空间或者不同的空间。第五提供了一个附件机制,每个广告都有附件,可以添加二进制的信息流。我们这个系统是2014年4月份上线,现在离线有一百多台机器,在线几千台机器,收入是每天几千万。
下面我会讲一下检索系统要解决的核心问题。我们把这个问题进行抽象之后可以看到,就是两个简单的问题。
第一个问题是用户特征和广告定向要求要能够匹配。广告的定向要求是一个逻辑表达式,在我们这里是递归定义的多叉树。例如一个用户画像,男性,27岁,广州。第二个问题是流量要求和广告属性的匹配,例如这里有两个广告,第一个广告属性是教育行业文字广告,检索系统要做的是在非常短的时间内对两个表达式匹配做快速的求解,我们可以在5毫秒之内对几十万复杂的表达式进行求解。怎么解决这个问题?因为时间要求特别苛刻,如果对每个递归的多叉树测试特征,是不可能在这么短的时间内完成操作。
我们进行了创新,把这个逻辑运算问题转换成了一个计数和查找的问题。首先我们把递归多叉树变成了OR—AND—OR表达式。当我们做了这个转置之后,单独处理OR节点。对于AND节点,我们要精确的存储下来,例如这里有一个例子,广告一,把AND节点变成了内部的数据结构,这里有一个命中计数三次,也就是说它需要被命中三次才能触发。对于20-30、40-50岁的用户,我们存储为匹配项1。这就是匹配的原子单位。大家可以看到这里有个区间的东西,是传统的结构中没有的,是我们架构比较好的创新。这个区间的意义是可以把很多离散的空间在索引上作为原子的匹配项。
有一种技术是把经纬度变成整数,你可以认为是一些小方块,去描述地图上不规则多边形,但是有了这个区间之后,就可以用大小不一样的方块描述同一个多边形,这样可以省下很多小方块结点。所以这个区间是我们的创新,当然整个算法是一个比较大的创新。
我们把所有这些递归多叉树都转置存储下来之后,就形成了索引文件。再看一下,用这些索引文件我们怎么去匹配?首先看到,最左边有一个用户画像,比如说27岁,他在倒排表里面,在最下面有几个入口,这时候我们扫到27岁的时候,可以对应到匹配项A的命中加1操作。同样对于男这个用户画像的属性,也可以对应到匹配项A的命中加1操作。达到3的时候,索引项对应的广告就能够全部被触发。
大家可以看到,第三代检索系统上线之后,除了前面讲到的产品特性提升之后,还有性能上的提升。这是我们的一些性能指标,我们也有很多关键特性,让广告在生命周期内缓慢播放,还有缓启动、急刹车。我们业务上线之后到现在发展比较顺利。现在每天是千万级,明年是每天将亿级的收入。我们在2015年底发现技术面临了新的挑战,来自于我们对人群的洞察和分析。这里举一个例子,比如说产品经理,可能希望能够找到广告人群中的一些铜牌会员,并且是活跃用户、男性。他希望找到这些种子用户,利用他们做相似人群的扩展。如果数据量比较小的时候,例如几百万,是比较容易的问题,但是如果是数据量特别大,比如说是几千万甚至几十亿、几千亿的时候,我们之前的方法是写了很多pig脚本程序去跑这个逻辑,但是这里有个冲突,产品经理需求非常多变,而且需要快速应对广告主。你去写脚本或者程序,需要程序员写代码,然后调试,这个过程比较慢,会产生一些问题。面对这个挑战,我们通过分析,利用已有的在检索上面的技术基础做了一些创新,我们研发了一个数据分析系统。
我们首先把这个问题简单化或者抽象化,这个数据分析问题可以分成四步,第一是有原始的数据集,它是弹性的,可大可小。然后对数据集进行过滤,抽出子集,例如抽出所有的男性,或者所有的会员。然后在子集上面进行分组操作,再进行一些运算。
我们也给自己定了一些系统设计的约束。首先需要可扩展,因为我们面临的数据规模是可变的,从几百万条到几千亿条都有可能。然后是高性能,这是我们技术能够产生价值的地方,如果能做到这样,整个项目的运维成本就会降下来。有比较高的易用性,因为我们当时做核心系统开发的人很少,只有三个人,但是我们面对的需求方,我们有一百多位程序员在做数据相关的操作。所以只用三个人怎么应对一百多人的开发团队,我们就要求这个系统必须有非常强的易用性。
我们通过技术讨论和创新,选择出一个架构,比较好的解决了所有的这些约束。我们的架构是基于SSD硬盘的检索架构,SSD硬盘越来越便宜,但是又提供了非常高的带宽和延迟,所以SSD是内存和传统硬盘之间的一个中间状态。这是我们的系统架构,首先系统分成全量和增量数据流,这样可以满足数据的准确性和及时性两种需求。
我们的索引分多片,例如一千片,利用多级聚合来加速。我们对外提供毫秒级的延时,能够提供同步的体验。之前大家使用PIG 可能需要一天能看到结果,现在我们用毫秒级就可以看到结果。我们集群上面会有Retrieval和Aggregator两种模块。Aggregator模块集成Mysql Proxy,提供了很大的便利。对于检索系统来说,它的核心设计要素是检索文件的布局,我们根据它的一些设计约束,选择了一个列存储。我们会把所有的列单独存储,这样可以对每个列提供比较好的压缩。倒排链选择RoaringBitmap,可以在性能和空间之间得到平衡。
前面讲的是怎么利用倒排来加速过滤的过程,就是怎么样用倒排在一个比较大的数据集里面抽取出一个比较小的数据集。接下来面对的问题是怎么样对比较小的数据集进行分组的操作。Group by有两种操作。我们经过研究自己的情况,发现这两种方法都不太适用。第一种方法,我们系统是对单列建索引,没有联合索引的设计。所以我们基于自己的数据结构研发两种方法,包括正排数据实现分组和倒排数据实现分组。通过分组性能对比,可以看出比原来的数据库算法优秀很多。
我们还提供了一个分区管理的功能,例如我们分析过去60天的数据,超过60天就可以简单把数据删掉。在查询的时候,也可以检索对应天的数据,而不用去检索全量的数据。还有比较有意思的插件功能,这是因为我们在PivotEngine的推广过程当中发现有很多需求难以用sql语言来满足,我们设计了一个插件架构。
我们系统的核心设计目标是性能和存储成本,我们的系统性能比Druid快一个数量级,存储成本也大幅度降低。
下面是我的总结。我们做了很多架构设计,出发点都来自真实的业务需求。我们这个部门本身也有一个比较特殊的技术生态,这也来自我们的业务特性,因为整个部门是一套架构。这样就要求我们整个团队需要比较密切的协作,需要互相理解对方的代码。对我们团队的代码能力要求很高,接口可读性要求也非常高,要求一个是技术生态体系。我们为充分利用数据建立了很多基础架构。另外广告系统这个行业,是一个技术密集的行业,技术能够推动产品的进步,能够对收入有影响。我们看到有一些关键业务的创新,例如兼容不同ID的能力,它能够帮助我们整合各种广告产品和广告形态。这些产品层面的创新背后的驱动力都来自我们在技术上的积累和创新。张家口下一代的全能广告系统架构
